Mapping Species From Crowdsourced Data Using Machine Learning
Using machine learning to generate geographical range predictions for tens of thousands of species with support from the Climate Change AI Innovation Grants Program.


The users of community science platforms such as iNaturalist (www.inaturalist.org) generate millions of photographic observations each month documenting where different plant and animal species can be found. In the last few years, advances in AI in the form of automated image classifiers allow non-experts to identify the different species that are present in these images. However, automatic species identification in images remains a challenging problem, as community science platforms can potentially contain images from hundreds of thousands of different species. One of the major sources of difficulty is that there can be multiple species that look visually similar (e.g. crows versus ravens), and thus remain very challenging for AI systems, and humans, to visually disambiguate.
Knowing where a species of interest is likely to be observed (i.e. its geographical range) is a valuable piece of information when trying to determine what species might be present in an image. Inspired by this simple observation, in recent work, we have developed efficient machine learning models that can take the location where an image was captured as input to determine which species are likely to be present at that geographical location. These models are trained on the locations of observations from iNaturalist, though there are many other platforms that it can be applied to.
Predictions about which species occur at a specific location can be combined with the predictions from automated image classifiers to enhance the accuracy of the final species estimate. We have found that this approach improves species classification performance in images from 75% to 82% when evaluated on a dataset that contains images from 40,000 different species from around the world. Importantly, this improvement does not necessitate any changes in the underlying image classifier being used.

Motivated by this success, we next wanted to understand how effective these models trained on crowdsourced location data are at predicting the ranges of species on a global scale. Unfortunately, unlike in the image classification example above where we could easily measure the improvement in the final image classification performance, assessing the accuracy of a predicted range for a species is a much more challenging problem. This is because, with some exceptions, there are no established benchmarks for this task.
To address this problem, we developed a suite of spatial prediction tasks for evaluating the performance of machine learning-based species range estimation models. Our new benchmark will enable researchers to evaluate different, and complementary, spatial prediction tasks, from estimating species’ ranges to quantifying how well these models help resolve mistakes in image classifiers. Despite being trained on spatially biased and incomplete data, we were able to show that it is possible to obtain performance that is within 75-80% agreement of expert-derived ranges across a wide set of species. These are promising initial findings, but also point to the fact that there is more work to be done to further improve performance on these spatial prediction tasks.

Main findings:
- Once trained, our range estimation models are compact and efficient to run. A single model smaller than 50MB can be used to predict the ranges for 47,000 different species.
- The performance of our models improves as we add more data during training, including from new species.
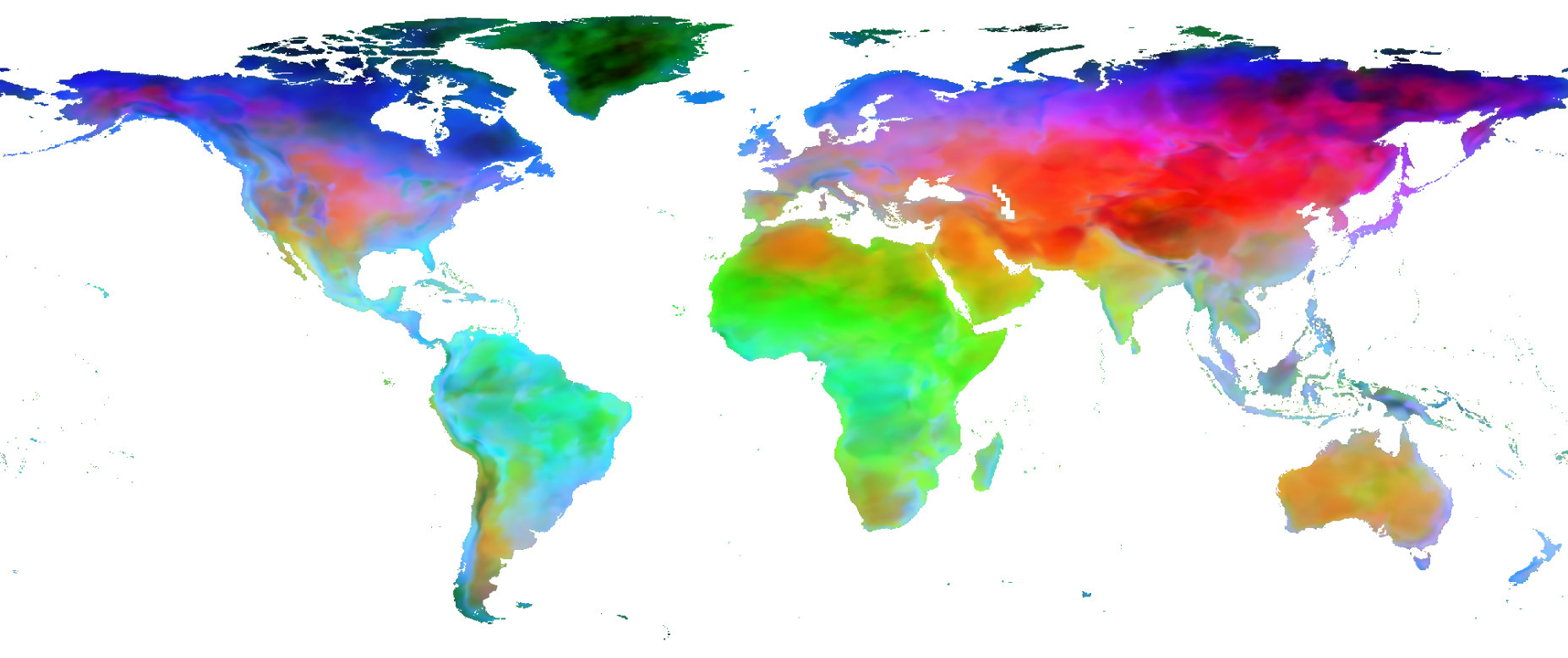
- Models trained without any explicit environmental information beyond geographical location can learn effective representations of space and also embed species with similar ranges close to each other (see below).
- Despite many of the biases present in the crowdsourced data we used to train our models, we observe that in many cases the predicted ranges are similar to the expert-defined ones.
- How a model is trained can have a significant impact on its performance. In the paper, we explore different ways of training these models and find that some ways lead to better performance. This opens many interesting doors for future progress on this task from both machine learning and statistics.

Going forward there are many interesting open questions that require additional investigation. For example, species observations from community science platforms can exhibit large geographical and temporal biases as some locations can be difficult for community scientists to reach. In addition, there are global biases as some of the most biodiverse locations on the planet are not yet well represented on these platforms. Some species are also much easier to photograph and identify than others; thus, detectability and data imbalance needs to be explicitly factored into our models. Care needs to be taken so that potential mistakes made by the range estimation models do not adversely impact the image classifiers and result in inaccurate identifications being made. These open questions mean that great caution should be exercised if attempting to make any conservation decisions based on the outputs of these current models.
In the future, we can expect to see more species observation data being uploaded to platforms such as iNaturalist. As the global reach of these online communities grows, we will also potentially obtain more data from currently underreported, but highly biodiverse, regions. Addressing the open methodological issues highlighted above will lead to a new set of methods that will be able to use this data to reliably estimate the ranges of previously mapped species. The resulting improved understanding of how different species are spatially distributed around the world will be an important piece of information in our quest to better conserve them.
More information about this work can be found in our recent paper titled “Spatial Implicit Neural Representations for Global-Scale Species Mapping” (https://arxiv.org/abs/2306.02564). The paper includes a detailed description of the models and our benchmark evaluation datasets and also includes a detailed discussion of the results. The work was presented at the International Conference on Machine Learning in July 2023.
Team members:
